2020/01/26 - [SQL] - [SQL] HackerRank로 시작하는 SQL - 7
[SQL] HackerRank로 시작하는 SQL - 7
2020/01/26 - [SQL] - [SQL] HackerRank로 시작하는 SQL - 6 [SQL] HackerRank로 시작하는 SQL - 6 2020/01/24 - [SQL] - [SQL] HackerRank로 시작하는 SQL - 5 [SQL] HackerRank로 시작하는 SQL - 5 2020/01/24 -..
jogamja.tistory.com
문제 : https://www.hackerrank.com/challenges/contest-leaderboard/problem?h_r=next-challenge&h_v=zen
Contest Leaderboard | HackerRank
Generate the contest leaderboard.
www.hackerrank.com
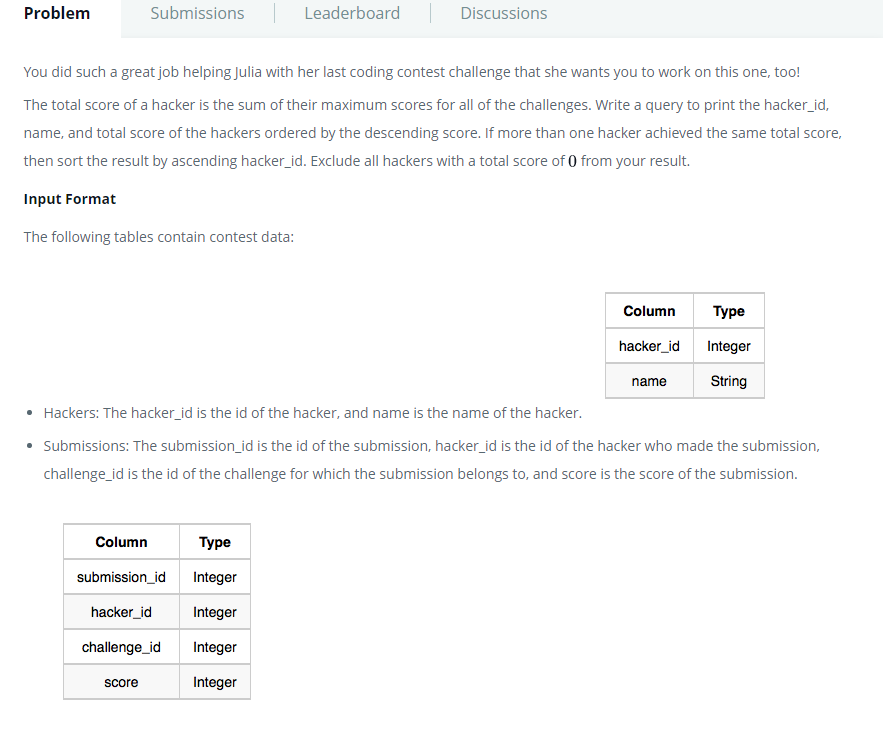
문제 : hacker_id, name, 총점을 출력해라. 단, 점수를 기준으로 내림차순으로 정렬해라. 여기서 총점이란, 각 대회에서 얻은 최고점의 총합을 의미한다. 만약, 동점자가 존재할시, hacker_id를 기준으로 오름차순으로 정렬하며 0점은 결과에서 제외해라.
서브쿼리에서 테이블로 보고 풀었다.
문제에서 얻은 깨달음은 밑에 임시저장할때 적어놨다.
SELECT H.HACKER_ID, H.NAME, SUM(S.max_s) as sum_s FROM HACKERS H, (SELECT HACKER_ID, CHALLENGE_ID, MAX(SCORE) as max_s FROM SUBMISSIONS GROUP BY HACKER_ID, CHALLENGE_ID) S
WHERE H.HACKER_ID = S.HACKER_ID
GROUP BY H.HACKER_ID, H.NAME
HAVING sum_s != 0
ORDER BY sum_s DESC, H.HACKER_ID ASC
-------------------------------------------------------------------------------------------------------------------
정답을 맞추긴했는데
마지막 GROUP BY H.HACKER_ID, H.NAME 을 해줘야 되는 이유를 모르겠따;
GROUP BY에 대해 이제 깨달았다고 생각했는데 풀때마다 의문.
--------------------------------------------------------------------------------------------------------------------
다시 생각해보니 서브쿼리에서
하나의 HACKER_ID에 대해 여러개의 MAX(SCORE) 가 존재하게 된다. -> 따라서 서브쿼리 S엔 하나의 HACKER_ID 가 COUNT(MAX(SCORE)) 개수만큼 존재.
그래서 WHERE문에서 H.HACKER_ID = S.HACKER_ID 를 할때 COUNT(max_s) 개만큼 생성되고 따라서
GROUP BY HACKER_ID를 해야된다. NAME도 하는이유는 당연히 H.HACKER_ID 만큼 H.NAME도 생성될거기 때문에...
애초에 GROUP BY를 해야 하나의 HACKER_ID에 대한 SUM을 구할수 있었다.
아직 medium단곈데 벌써 어렵다;
임시저장 제목으로 쓴 글들은 나중에 수정해서 올리겠다.
'SQL' 카테고리의 다른 글
| [SQL] HackerRank로 시작하는 SQL - 7 (0) | 2020.01.26 |
|---|---|
| [SQL] HackerRank로 시작하는 SQL - 6 (0) | 2020.01.26 |
| [SQL] HackerRank로 시작하는 SQL - 5 (0) | 2020.01.24 |
| [SQL] PRG's SQL DOCS (0) | 2020.01.24 |
| [SQL] HackerRank로 시작하는 SQL - 4 (0) | 2020.01.24 |



댓글