2020/01/05 - [Python] - [Python] lxml, request 조합으로 뉴스기사 크롤링하기 -2
[Python] lxml, request 조합으로 뉴스기사 크롤링하기 -2
코드 작성환경은 구름ide 우분투 18.0 버전에서 작성했고, python3 입니다. 2020/01/04 - [Python] - [Python] lxml, request 조합으로 뉴스기사 크롤링하기 -1 [Python] lxml, request 조합으로 뉴스기사 크롤링..
jogamja.tistory.com
이번엔 크롤러를 모듈화 하고 크롤링한 결과를 MongoDB에 저장해봅시다.
시작하기전에 MongoDB가 설치되어있어야 하며, pymongo도 pip로 설치해줍시다.
import requests, time
from lxml.html import fromstring
import concurrent.futures
from multiprocessing import Pool
from pymongo import MongoClient
class NewsCrawler:
####
##Logics
####
def __init__(self):
self.articles = []
def _getParserPage(self, page):
url = 'https://news.joins.com/sports/baseball/list/' + str(page) + '?filter=All'
res = requests.get(url)
parser = fromstring(res.text)
return parser
def _getArticles(self, parser):
article_list = parser.xpath('//div[@class="list_basic"]')
parsed_articles = article_list[0].xpath('.//li')
return parsed_articles;
def _getLinks(self, parsed_articles):
links = []
for article in parsed_articles:
parsed_link = article.xpath('.//a[@href]')
link = parsed_link[0].get('href')
links.append(link)
return links;
def _getTextUrl(self, link):
url = 'https://news.joins.com'
new_url = url + link;
res = requests.get(new_url)
return {'content' : res.text, 'link' : new_url}
def _processArticles(self, infos):
articles = [];
for info in infos:
parser = fromstring(info['content'])
article_form = parser.xpath('//div[@id="body"]')[0]
subject = article_form.xpath('.//div[@class="subject"]/h1/text()')[0]
article_body = article_form.xpath('.//div[@id="article_body"]')[0].text_content()
article_content = article_body.replace('\xa0','\n')
article = {'title' : subject,'link' : info['link'], 'content' : article_content}
articles.append(article)
return articles
def _crawlingNews(self, page):
result_articles = [];
while(True):
parser = self._getParserPage(page)
p_arts = self._getArticles(parser)
if (len(p_arts) == 0):
break
links = self._getLinks(p_arts)
infos = []
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = []
for link in links:
future = executor.submit(self._getTextUrl, link);
futures.append(future)
for future in futures:
infos.append(future.result())
articles = self._processArticles(infos)
result_articles.append(articles)
page += 8;
return result_articles
####
##Main
####
def work(self):
print('START')
pages = [i+1 for i in range(8)]
pool = Pool(8)
self.articles = pool.map(self._crawlingNews,pages);
pool.close()
pool.join()
print('END')
def updateDB(self):
print('START')
client = MongoClient() # default localhost, 27017 port
db = client['db_newsArticles']
table_articles = db['Articles']
for page, _articles in enumerate(self.articles):
if _articles is []:
continue
for article_list in _articles:
for article in article_list:
query = {'title' : article['title']}
table_articles.update_one(query, {'$set' : article}, upsert = True)
print('END')
if __name__ == '__main__': ## 모듈 테스트할때만 작동
Crawler = NewsCrawler();
Crawler.work()
Crawler.updateDB()
[전체코드]
변경,추가된거 위주로 봅시다.
일단 NewsCrawler 구조는 work 로 크롤링을 하면 self.articles 에 저장하는 구조입니다.
db 올리는건 updateDB로 합니다.
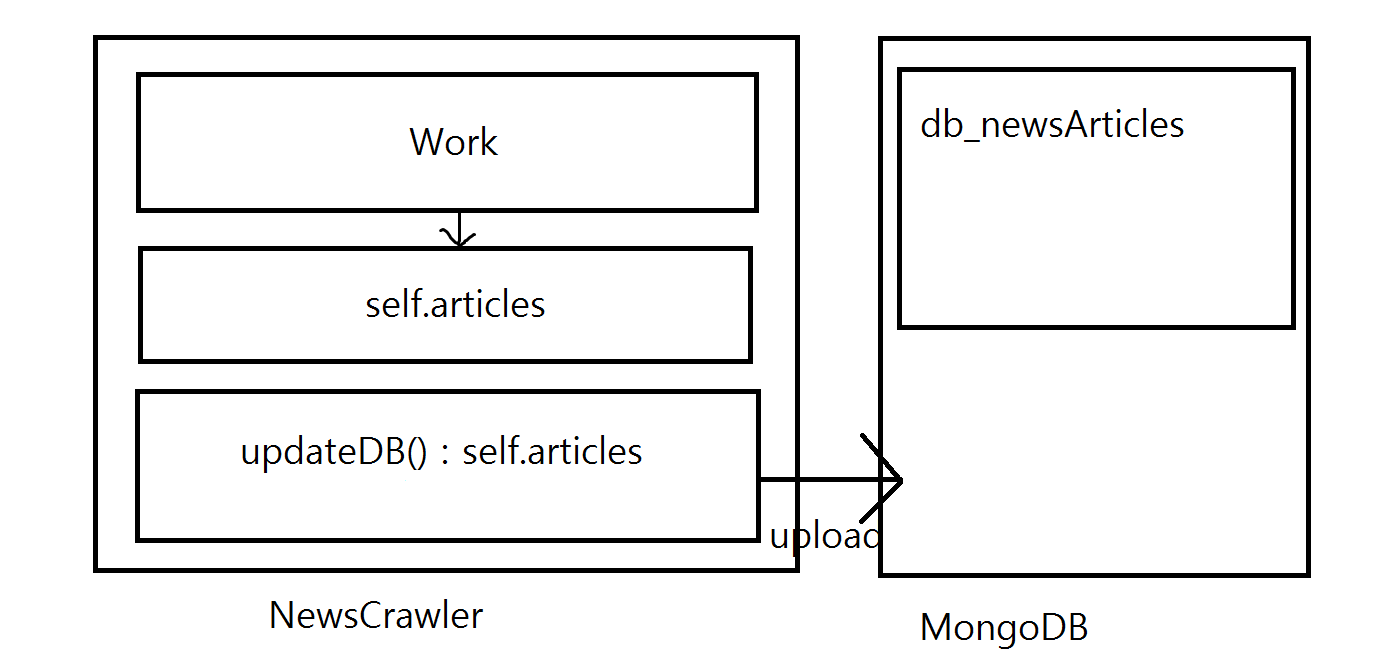
대충 그려보자면 이런구조..
저는 MongoDB에 db_newsArticles 데이터 베이스를 만들었고, 그안에 collection ( mysql의 table에 해당) 은 Articles로 했습니다. 몽고DB는 각자 설치했다는 가정하에 하겠습니다.. -> 나중에 글로 작성할게요
생성방법은 다음과 같습니다.
db생성
use db_newsArticlescollection 생성
db.createCollection("Articles")
다시 코드로 돌아가서 work부분은 기존 테스트와 같으니깐 생략하고
updateDB위주로 볼게요.
Articles collection에 접근하는 코드입니다.
client = MongoClient() # default localhost, 27017 port
db = client['db_newsArticles']
table_articles = db['Articles']
update
for page, _articles in enumerate(self.articles):
if _articles is []:
continue
for article_list in _articles:
for article in article_list:
query = {'title' : article['title']}
table_articles.update_one(query, {'$set' : article}, upsert = True)self.articles의 구조는 [[1page], [2page], .... [8page]] 이렇게 있습니다.
또, 각 페이지는 [{'title' : 제목 , 'link' : 주소 , 'content' : 내용} , {...}, ...}] 이렇게 되있습니다.
이에맞게 순차적으로 접근해준걸 알 수있습니다.
또, 같은글을 중복되게 저장하는건 정말 비효율적인 일입니다. 그래서 update에서 upsert = True 옵션을 사용했습니다.
upsert = True이면 query에 해당하는 조건에 대해 중복되면 등록하지 않습니다.
코드를 실행해보고 , db.Articles.find({}) 로 db에 데이터들이 등록됬는지 확인해봅시다.

잘 나오네요!
몽고db 사용법에 대해 좀 자세히 안쓴거같은데 궁금한거 있으면 댓글 남겨주세요
다음글에서는 excel 저장과 NewsCrawler 확장을 해봅시다.
'Python' 카테고리의 다른 글
| [Python] lxml, request 조합으로 뉴스기사 크롤링하기 -2 (0) | 2020.01.05 |
|---|---|
| [Python] lxml, request 조합으로 뉴스기사 크롤링하기 -1 (0) | 2020.01.04 |
| [Python] argument를 bind하려면 ?? (partial) (0) | 2020.01.04 |
| [Python] BeautifulSoup 으로 크롤링하기 (0) | 2019.11.10 |


댓글