처음에 lxml으로 html파싱을 하면서 절대경로로 탐색하는 바람에 삽질을 많이했었다.
// : 절대경로 , .// : 현재 Node에서 탐색
사용법을 기록해두기위해 간단한 뉴스기사 크롤러를 만들어봤다.
https://news.joins.com/sports/baseball/list/1?filter=All
스포츠 > 야구 뉴스 - 중앙일보
스포츠 > 야구 뉴스 - 중앙일보 - 야구, 해외야구, 축구, 해외축구, 농구/배구
news.joins.com
우리가 크롤링할 뉴스사이트는 여기다.
먼저 크롬으로 구조부터 살펴보자.
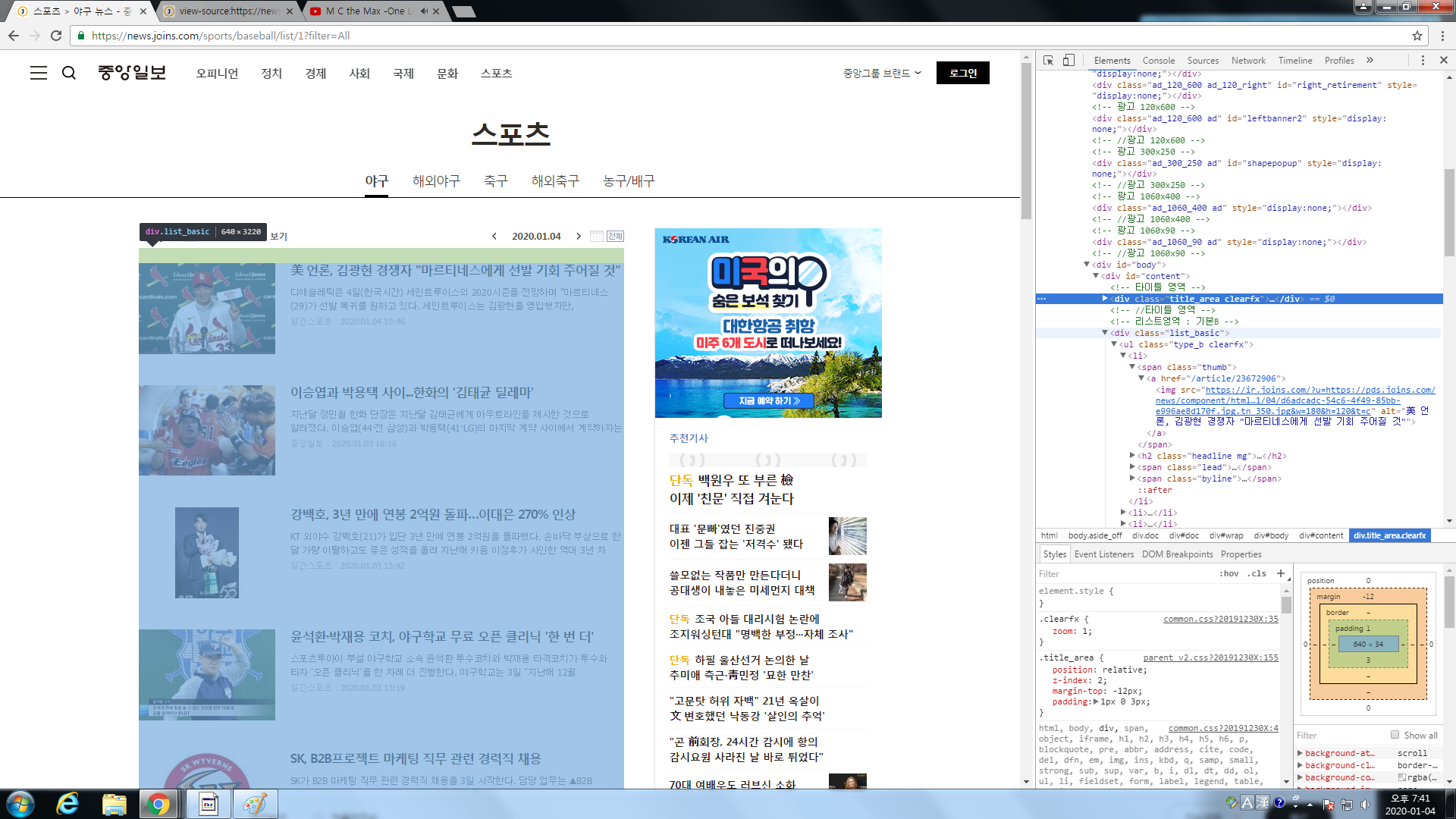
div[class=list_basic] 안에서 li안에 기사들의 정보가 존재하는걸 알수있다.
일단 link부터 뽑아오자.
일단 모듈들을 import하자.
import requests
from lxml.html import fromstringurl을 설정하고 html파싱을 한다.
url = 'https://news.joins.com/sports/baseball/list/1?filter=All'
res = requests.get(url)
parser = fromstring(res.text)article_list = parser.xpath('//div[@class="list_basic"]')
parsed_articles = article_list[0].xpath('.//li')links = []
for article in parsed_articles:
parsed_link = article.xpath('.//a[@href]')
link = parsed_link[0].get('href')
links.append(link)
print(links)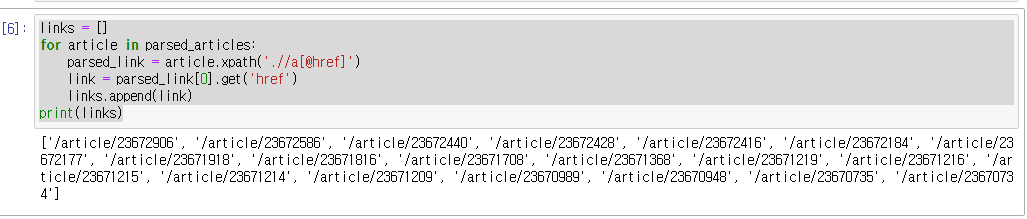
성공적으로 기사주소를 가져왔다.
이제 기사 내부로 들어가보자.
똑같이 크롬으로 확인하자.
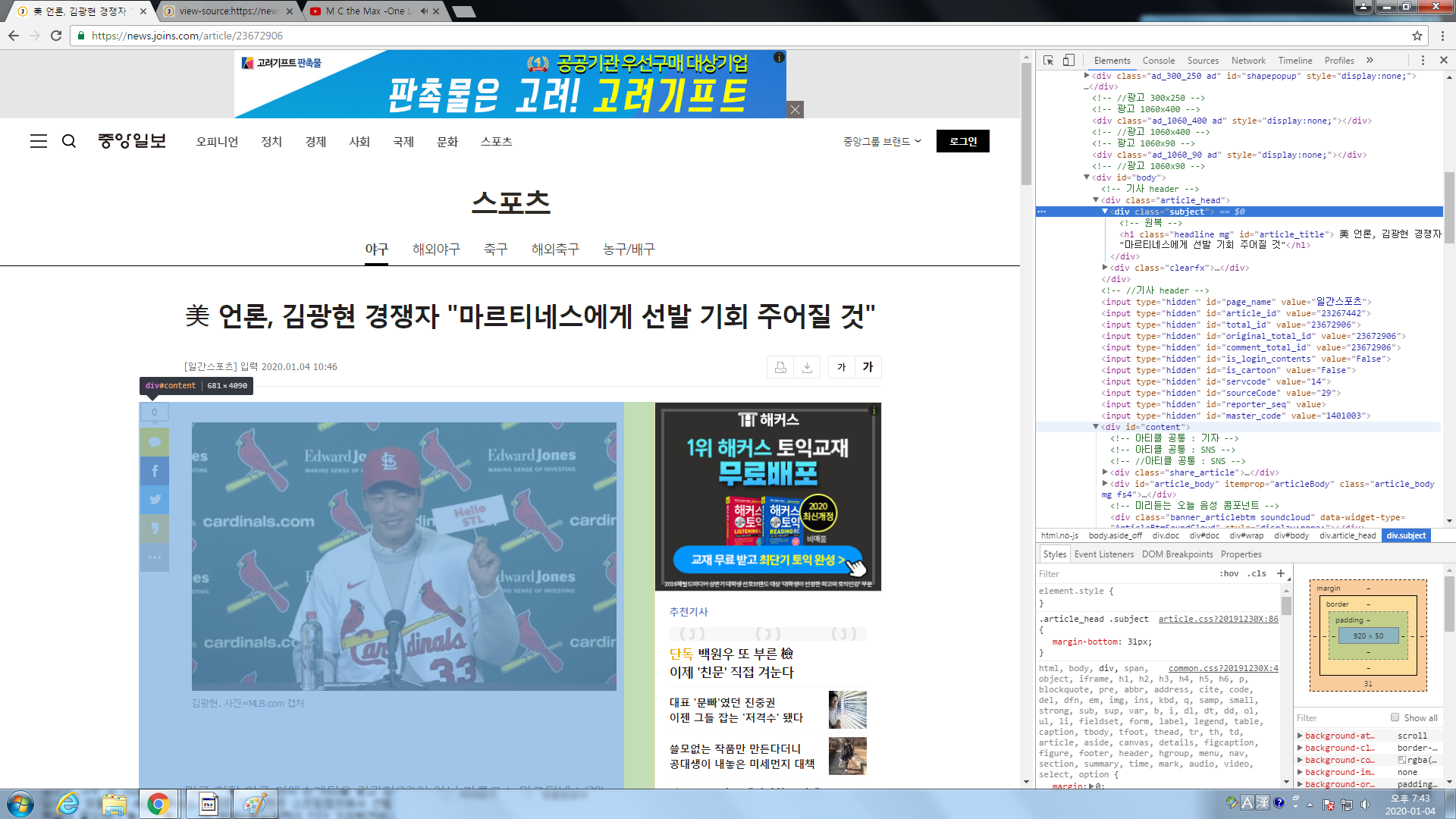
div[id=body] 에 기사가 존재하는걸 알수있다.
div[class=subject] 는 제목 div[id=content] 는 내용이다. 이제 정보만 뽑아오면된다.
url = 'https://news.joins.com'
articles = [];
for link in links:
new_url = url + link;
res = requests.get(new_url)
parser = fromstring(res.text)
article_form = parser.xpath('//div[@id="body"]')[0]
subject = article_form.xpath('.//div[@class="subject"]/h1/text()')[0]
article_body = article_form.xpath('.//div[@id="article_body"]')[0].text_content()
article_content = article_body.replace('\xa0','\n')
article = {'title' : subject,'link' : new_url, 'content' : article_content}
articles.append(article)
print(articles)
결과는 성공적이다.
하지만, 우리는 아직 1page밖에 크롤링 하지않았다.
https://news.joins.com/sports/baseball/list/"page"?filter=All우리는 주소에서 page 부분이 각 페이지를 의미하는걸 알수있다. 그렇다면 page가 실제 있는거보다 크면 어떻게 될까?

보다시피 주소는 적용되나 기사가 없는걸 알수있다. 이점을 이용해서 크롤링을 해보자.
articles = []
page = 1
while (True):
url = 'https://news.joins.com/sports/baseball/list/' + str(page) + '?filter=All'
print(url)
res = requests.get(url)
print(page)
parser = fromstring(res.text)
article_list = parser.xpath('//div[@class="list_basic"]')
parsed_articles = article_list[0].xpath('.//li')
if (len(parsed_articles) == 0):
break
links = []
for article in parsed_articles:
parsed_link = article.xpath('.//a[@href]')
link = parsed_link[0].get('href')
links.append(link)
url = 'https://news.joins.com'
articles = [];
for link in links:
new_url = url + link;
res = requests.get(new_url)
parser = fromstring(res.text)
article_form = parser.xpath('//div[@id="body"]')[0]
subject = article_form.xpath('.//div[@class="subject"]/h1/text()')[0]
article_body = article_form.xpath('.//div[@id="article_body"]')[0].text_content()
article_content = article_body.replace('\xa0','\n')
article = {'title' : subject,'link' : new_url, 'content' : article_content}
articles.append(article)
page += 1
print(articles)바뀐부분은 주소부분에 str(page) 와 parsed_articles의 길이 조건 부분이다.
다음 글에서는 multiprocessing 을 통해 속도를 높여보고, 크롤링한 기사 정보들을 db에 올리거나 엑셀로 관리할수있게 만들어보자.
'Python' 카테고리의 다른 글
| [Python] lxml, request 조합으로 뉴스기사 크롤링하기 -3 (0) | 2020.01.05 |
|---|---|
| [Python] lxml, request 조합으로 뉴스기사 크롤링하기 -2 (0) | 2020.01.05 |
| [Python] argument를 bind하려면 ?? (partial) (0) | 2020.01.04 |
| [Python] BeautifulSoup 으로 크롤링하기 (0) | 2019.11.10 |


댓글